Designing an Asynchronous World with Event Driven Architecture
High availability, scalability, cost optimization, configuration instead of code, and minimal infrastructure management. This is how you can summarize AWS’ serverless concept. It isn’t new and many know and use it. But new products and enhancements to some familiar services, especially with regard to event-driven architectures, are shedding a new light on the subject and giving rise to the term “the new serverless”. This article will examine what this means and how it can be implemented in practice.
The world is asynchronous
At the re:Invent 2022 conference, Dr. Werner Vogels emphasized that synchronous software development is a mental simplification and therefore, an illusion. However, the world is asynchronous and software should reflect this. It’s frustrating for users when programs stop responding to input during time-consuming operations.
The incremental query strategy is often used to circumvent this problem on the front-end side. On the backend side, synchrony comes into play in a slightly different form, but it can be compared to imperative software development. When a command is received, the actions are invoked in sequence. This results in tight coupling, and failure can destabilize the entire application. When failure occurs in an event-driven architecture, only one component is affected, while the rest function properly.
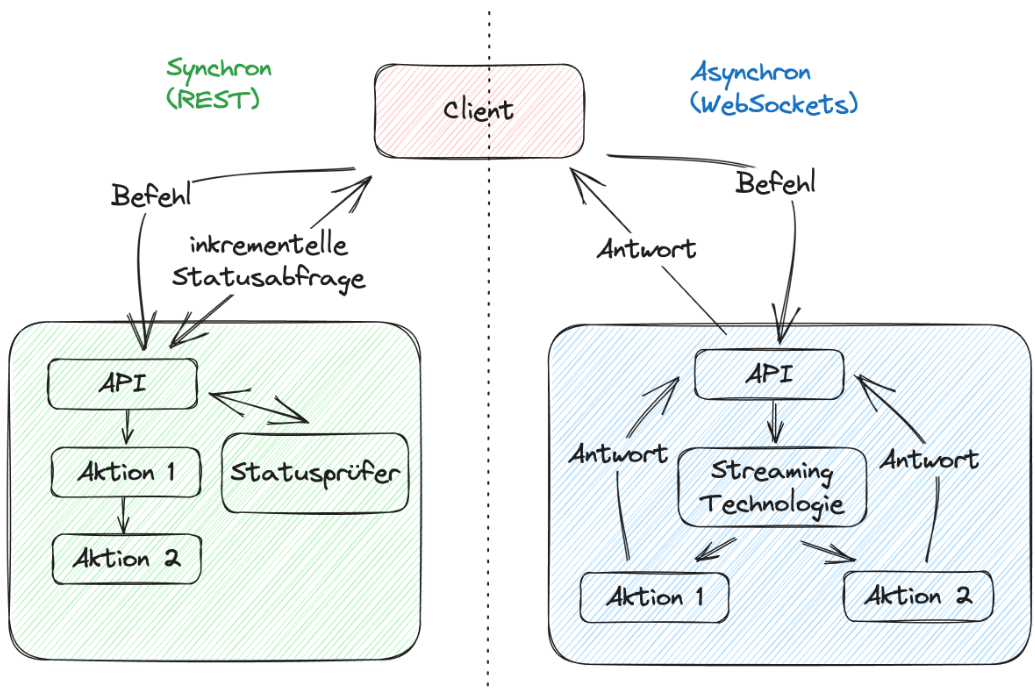
Fig. 1: Comparing synchronous vs. asynchronous processing
Current implementation practice
On one hand, AWS is improving services, creating new solution capabilities, and training their usage. But on the other hand, the requirements on behalf of developers and architects are characterized by old, tried and true practices. Recurring patterns are evident in many projects. One of which is the direct processing of calls to the API gateway by a Lambda function.
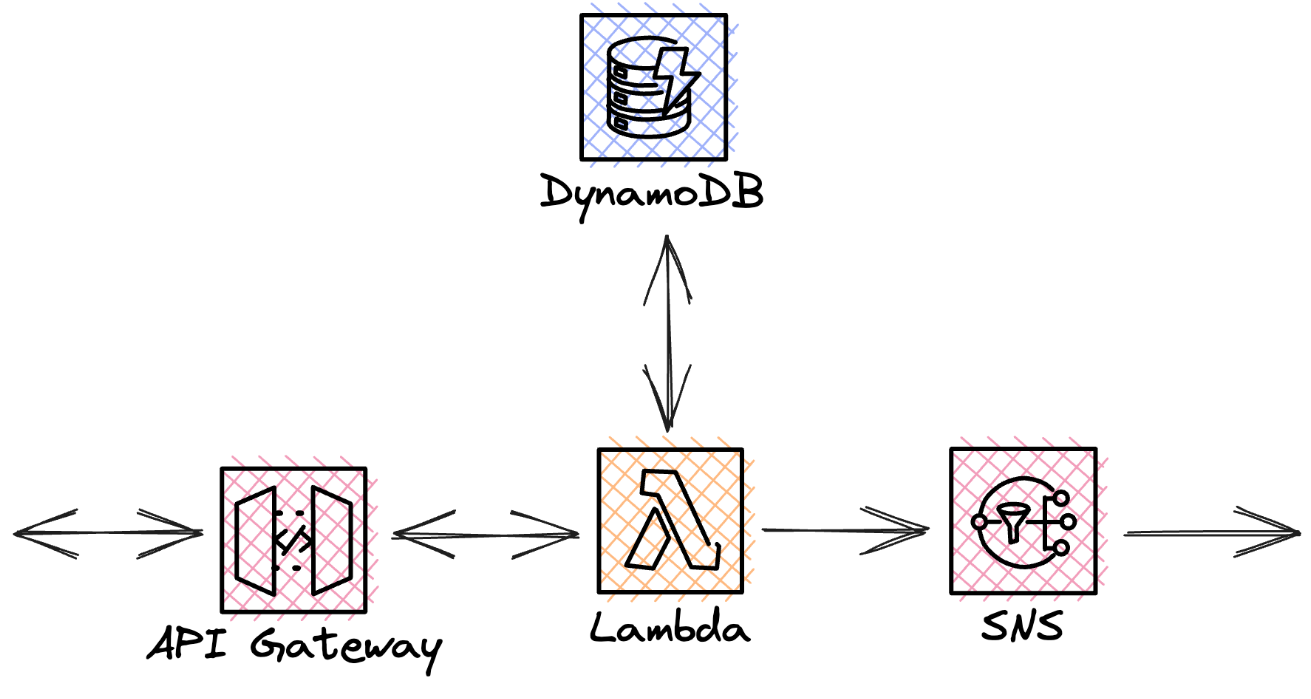
Fig. 2: A simple approach
This is an example of a simple microservice that accepts a task from a user, performs the necessary calculations with a database, returns the response to the user, and optionally passes the transformed data to a PubSub service for further operations. The Lambda function contains the glue code for transporting data between the services and performs the actual task and processing. This architecture is justified in simple cases, but it has some problems. The fact is that it is a synchronous process. For calls that take longer, the frontend is blocked and users have to wait for the response before executing the next action. An intelligent UI design can be the solution. If an application has only a few users, this shouldn’t be a problem anyway. However, Lambda limits the number of concurrent calls to 1000 per AWS account. If there are a large number of requests with long processing times, throttling and data loss cannot be ruled out. One example use case is a global online marketplace with content review or AI image generators with many users. However, it doesn’t have to be the user. Machine data collection can also lead to the same result. In this scenario, scalability is limited and the problem should be solved differently.
A step towards asynchrony: Storing events
The example of the abstract online marketplace illustrates step-by-step how asynchrony can be introduced with the help of an event-driven way of thinking. In practice, the first change is as follows:
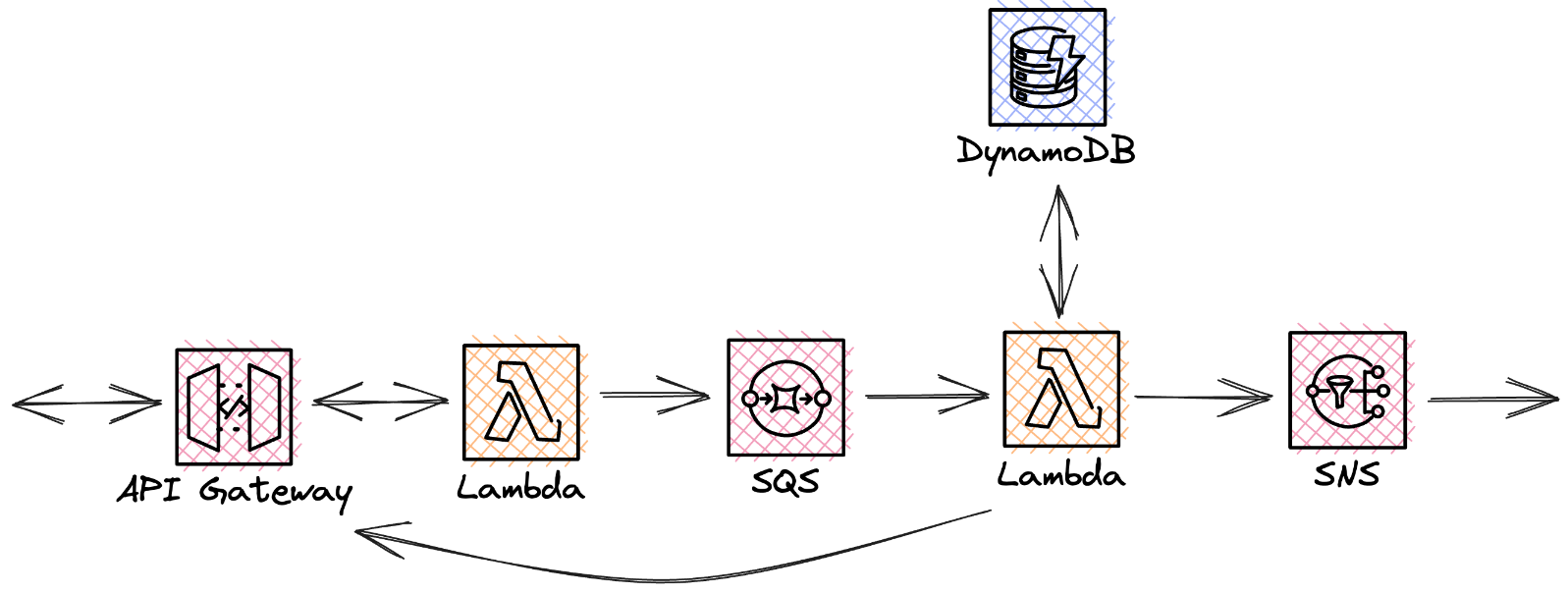
Fig. 3: SQS to prevent message loss.
When a call is received in the API gateway, a function is called to forward the message to the SQS queue. This must be short-lived and provide a response to the frontend as quickly as possible. The return value may simply be HTTP 202 command accepted or the location of potential further processing results. Here, the queue has the function of a buffer in case the next, more time-consuming function fails. Data is stored and processed when the traffic slows down. The processing Lambda is further tasked with implementing the business logic using the database and making sure the results are delivered to the PubSub notification service. An extra burden is delivering the results to the API gateway, ultimately, to the original caller. This is where the issue of WebSockets or GraphQL subscriptions comes up again. The API gateway must be configured accordingly to enable this.
This solution introduces asynchrony, avoids potential data loss, and provides better data flow. Productive use is justified, but we can’t call it event-driven architecture yet. What vulnerabilities do we still need to address?
- Scalability: All traffic is still handled by a single processing function, which can lead to increased latency for large amounts of data.
- Single Responsibility Principle: The processing Lambda contains the transport logic, domain knowledge, and performs the role of an ORM. It is a clear violation of the single responsibility principle.
- Debugging: It is difficult to debug because there is a lot of Lambda code instead of infrastructure configuration.
- Operation: You need to implement your own solutions for error handling and retrying failed calls. This increases the time needed for the entire function call in the event of an error, increasing costs.
- Cost: There is a higher total cost of ownership due to higher development and eventual maintenance costs for functions.
In summary, the Lambda functions are the biggest weakness in this architecture. Instead of orchestration code, a standardized solution should be used.
AWS StepFunctions Express Workflows: Use Lambdas for Business Logic Only
Obviously, the all-rounder Lambda function is the main problem factor in the overall architecture. It should be subjected to restructuring first. AWS StepFunctions can be used for this. This is a visual workflow orchestrator service that enables and manages invocations of other services in a state-based manner. It also has built-in exception handling and fast, cost-saving retries. There are two kinds of workflows that can be defined: the long-lived standard workflows and express workflows, which are ideal for high-throughput event-driven architectures. The entire function can be replaced with the following workflow:
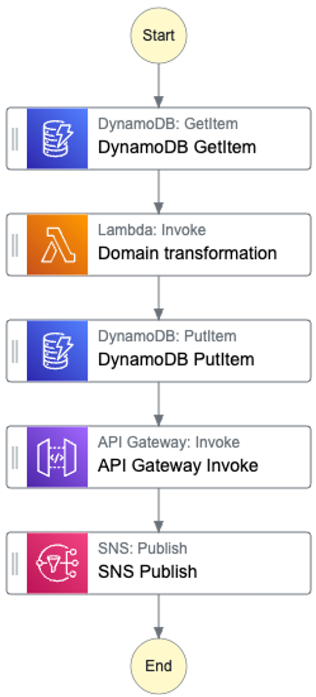
Fig. 4: StepFunction definition
The orchestrator sends the queries to the database, executes the business logic function, reports the result back to the user with the API gateway call, and passes it to SNS. The pure domain transformation is the task of the streamlined Lambda function. It must deterministically transform inputs into outputs. This should take only a few milliseconds. In some cases where the necessary transformations are trivial, you can use built-in intrinsic functions instead of Lambda. This can very simply transform data. These are divided into the following categories:
- Arrays
- Data encoding and decoding
- Hash calculation
- JSON manipulation
- Mathematical operations
- String operations
- ID generation
- Generic operations (currently only formatting)
A prerequisite for using them is the appropriate syntax in the state definition. For example:
Input:
{ “number”:127 } Operation: { „output.$“: „States.MathAdd($.number, 1)“ }
The dollar sign indicates that an object field from the input is used. In this case, number is specified in JSONPath notation. In the output, this character is no longer present.
Output:
{ „output“: „128“ }
Internally, all communication to AWS services is handled natively with the SDK, which guarantees a high level of reliability and speed.
Thanks to the high-quality logger, even non-technical people can understand an error in the system and easily fix it in a visual editor.
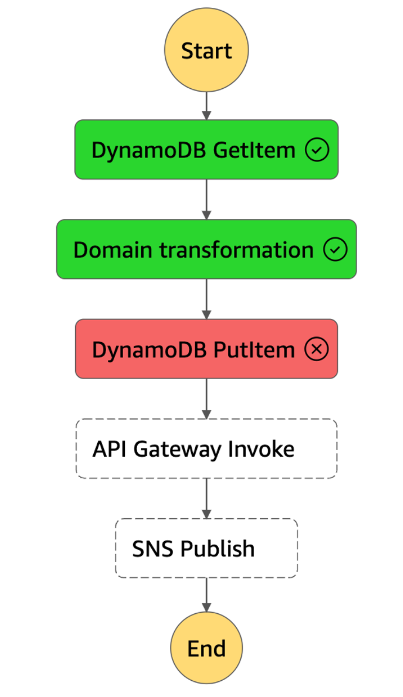
Fig. 5: StepFunction failure
An error occurred while executing the state ‘DynamoDB PutItem’ (entered at the event id #12). The JSONPath ‘$.lamdaOutput.naRme’ specified for the field ‘S.$’ could not be found in the input ‘{“lambdaOutput”:{“name”:”Welcome to new serverless”}}’
Obviously, there was a typo in configuration, which should be easy to fix.

Fig. 6: Typo in a DynamoDB step’s configuration
EventBridge Pipes: A cheer for the serverless data transport service
Unfortunately, there’s no direct connection between SQS and StepFunctions. For this, a Lambda function would need to be written to act as a bridge. How can we solve this problem? EventBridge pipes come to the rescue. Launched in December 2022, the pipes provide point-to-point integration between event producers and consumers as part of the EventBridge service. Event filtering and transformation are offered as an integrated feature. Transformation is possible with AWS StepFunctions. What does this mean for the architecture? Pipes are used to intercept messages from the SQS, transform them with StepFunctions, and forward them natively to the SNS! This makes SNS:Publish in Express Workflow obsolete and it can be removed.

Fig. 7: EventBridge Pipes Workflow
With a small API gateway update, you can also get rid of the unwanted transport Lamba and send messages directly to the queue. Here, HTTP 202 request accepted is always returned in response. The resulting architecture looks like this:
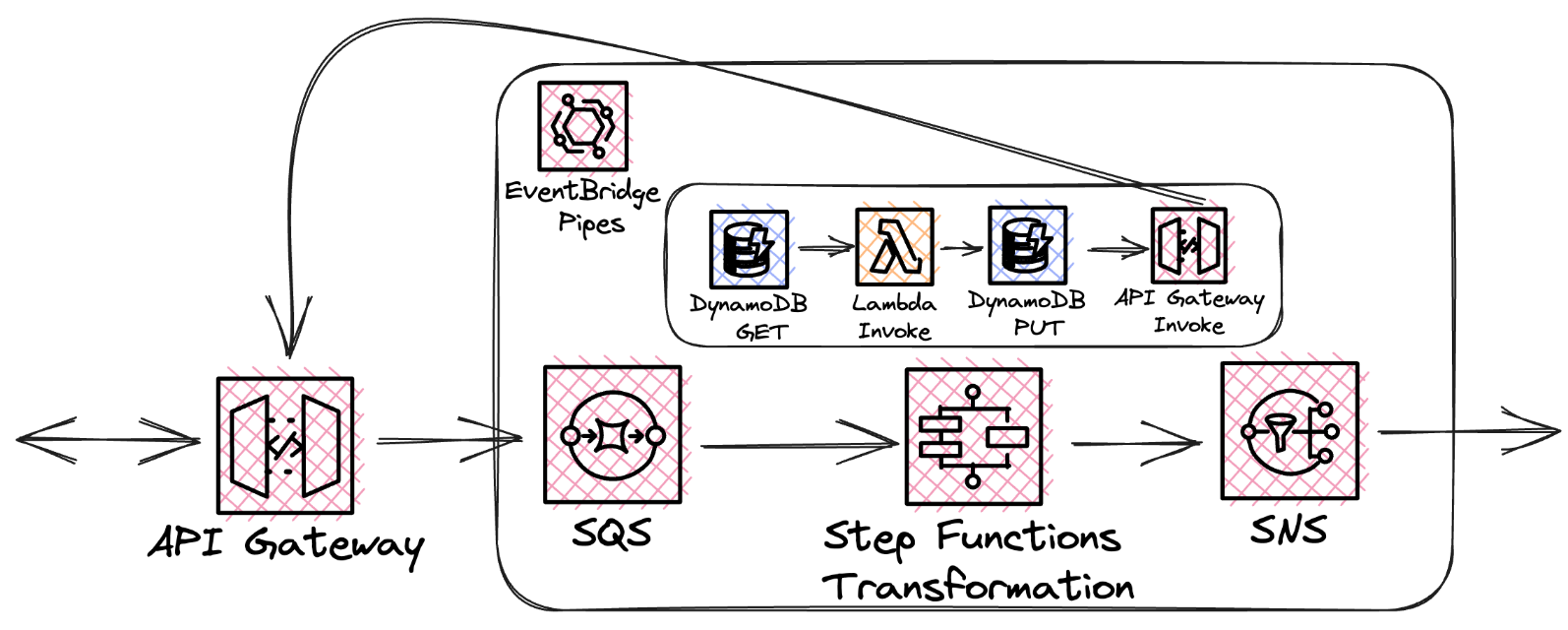
Fig. 8: Architecture with EventBridge Pipes
With regard to the original architecture’s problems, we can draw the following conclusions:
- Scalability: All traffic is handled by a single StepFunction that uses the business logic Lambda. The problem partially remains. Loading independent commands can be distributed.
- Single Responsibility Principle: Responsibilities were divided. Pipes handle data transport, Lambda handles business logic, and StepFunctions handles communication with other AWS services. Alternatively, feedback to the API gateway can be done with a separate microservice.
- Debugging: With built-in logging and error handling, troubleshooting can potentially be performed by non-technical personnel.
- Operation: AWS provides built-in solutions in StepFunctions for handling exceptions and performing retries.
- Cost: Development and eventual maintenance costs are significantly reduced in comparison and therefore, so is the total cost of ownership.
Scalability How-To: Event-driven architecture through streaming technologies
The main problem with the current architecture is that a message from the queue can only be forwarded to a consumer. Afterwards, it is removed from the queue. Of course, there are circumstances where we may want this behavior, but not in this instance. An event-driven architecture is characterized by the fact that a single message can be sent to multiple recipients who decide what to do with it. How can we achieve this? By introducing event streaming. Possible serverless candidates are:
- Amazon Kinesis Data Streams – AWS-owned real-time streaming service. Messages are held in memory for a defined period of time.
- Amazon Managed Streaming for Apache Kafka (MSK) – Apache Kafka on AWS. Clusters and brokers are managed by AWS, but the creation of topics, partitions, etc. is left up to the user.
- Amazon EventBridge Event Bus – EventBridge is a PubSub event bus for messages to be distributed to additional microservices.
We select the first candidate to simplify further implementation. Kinesis Data Streams provides automatic configuration for the entire infrastructure and dynamic scaling. Message order is preserved at the shard level. A shard can be considered to be a partition. Messages with the same partitionKey always end up on the same shard, so actions where the correct order is important should be grouped together. Replacing SQS with this streaming service results in the following architecture:
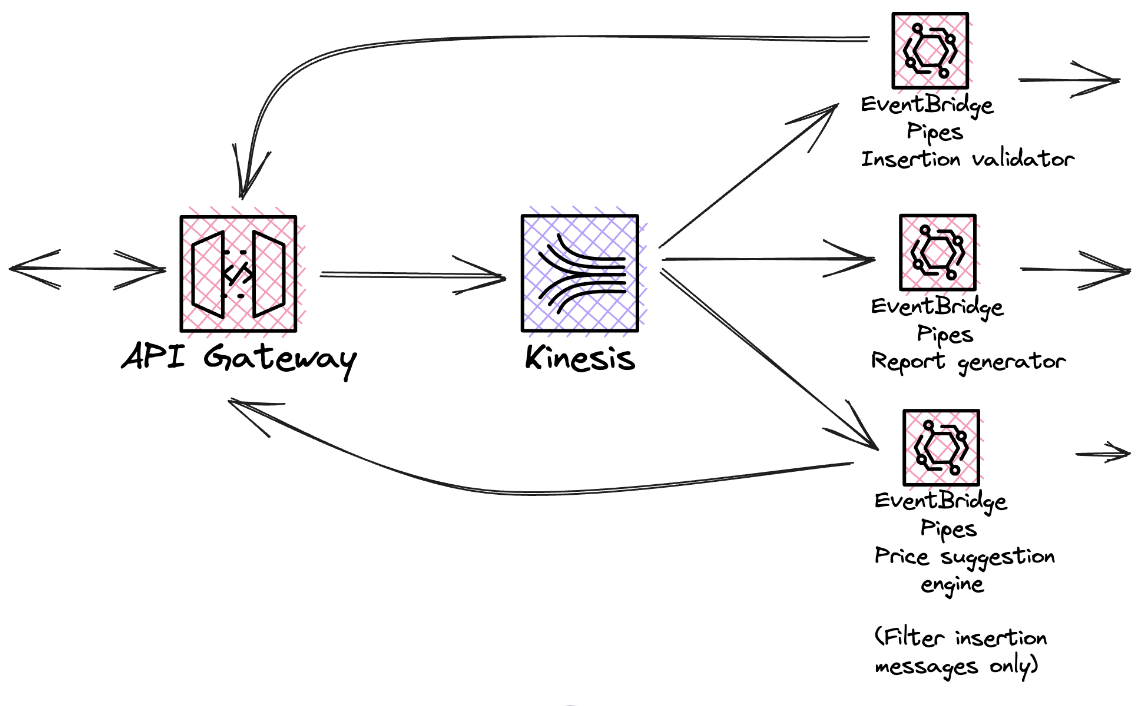
Fig. 9: Final event-driven architecture
Each addressee can filter the messages they want to receive. They only pay for those that are not filtered out and processed. Processing is done asynchronously, independently, and in parallel. Throughout the system, Lambda functions, if present, only serve domain transformation.
Infrastructure Automation with the AWS Cloud Development Kit (CDK)
The entire infrastructure can be defined in code. Deployment can be automated. This is done with the Infrastructure as Code tool AWS CDK. This is a framework that allows you to define resources in a programming language that the developer is familiar with: TypeScript, JavaScript, Python, Java, C#/.Net, and Go. TypeScript is used for further implementation. AWS CDK is an abstraction of AWS CloudFormation, a provisioning engine that accepts infrastructure configuration files in JSON or YAML. Therefore, the framework synthesis process results in a JSON file. The documentation describes the first steps with the tool.
It is recommended that you start with the project in the terminal:
mkdir new-serverless
cd new-serverless
As already mentioned, implementation is done in TypeScript. However, the syntax is similar in all supported languages and can be transferred without any problems.
cdk init app –language typescript
The lib folder contains the file new-serverless-stack.ts, whose constructor defines the infrastructure. First, the commented out sample code must be removed, then we can start the implementation.
The first step is to create the API gateway in the websocket version and the Kinesis stream.
const apiGateway=new CfnApi(this, 'Api', { protocolType: 'WEBSOCKET', routeSelectionExpression: '$request.body.action', name: 'new-serverless-api' }); const kinesisStream = new Stream(this, 'Stream', { streamName: 'new-serverless-stream' })
One of the interesting parameters here is the routeSelectionExpression. Depending on what is passed in the query under the action key, appropriate routing takes place.
Here is a short explanation as to why one class starts with Cfn and the other does not. The Cfn resource is a Level 1 resource, which is automatically generated directly from the CloudFormation resources. Above that, there are the Level 2 resources, which are abstractions of the Cfn resources with a more convenient to use API. These must be implemented in the framework first. Both allow the construction and reuse of Level 3 constructs, which are more complex infrastructures.
The next step is integrating these services.
const apiGatewayRole = new Role(this, 'Role', { assumedBy: new ServicePrincipal('apigateway.amazonaws.com') }); kinesisStream.grantWrite(apiGatewayRole) const kinesisPutRecordTemplate = { StreamName: kinesisStream.streamName, Data: '$util.base64Encode($data)', PartitionKey: "$input.path('$.action')" }; const kinesisIntegration=new CfnIntegration(this, 'KinesisIntegration',{ apiId: apiGateway.attrApiId, integrationType: 'AWS', requestTemplates:{ 'application/json': '#define( $data) { \"connectionId\": \"$context.connectionId\", \"payload\" : $input.body } #end '+JSON.stringify(kinesisPutRecordTemplate) }, credentialsArn: apiGatewayRole.roleArn, integrationMethod: 'POST', integrationUri: `arn:aws:apigateway:${this.region}:kinesis:action/PutRecord` }); const kinesisRoute= new CfnRoute(this, 'KinesisRoute', { apiId: apiGateway.attrApiId, routeKey: 'longRunningRequest', target: 'integrations/'+kinesisIntegration.ref });
The role enables sending a message from the API to the stream. The kinesisPutRecordTemplate object is a template for this. The data must be base64 encoded and the partitionKey is taken from the request like the routing. For the integration object, the Velocity Template Language (VTL) [4] is also used to get the connectionId of the connection and to pack the content of the request into the payload object. Finally, a routing is created that’s triggered when longRunningRequest is set under the request’s action key. The integration reference is specified in the target parameter. This means that the information isn’t known until deployment time and is set accordingly.
Only the stage is missing for the API gateway.
const apiStage= new CfnStage(this, 'Stage', { apiId: apiGateway.attrApiId, stageName: 'dev', autoDeploy: true }); new CfnOutput(this, 'WebSocketURL', { value: `${apiGateway.attrApiEndpoint}/${apiStage.stageName}` })
The autoDeploy parameter must be used with caution. If set, the stage is overwritten with every change, which is not always desirable. But this is useful for prototyping. Additionally, a CfnOutput is created. Its value is the address of the WebSocket API where a connection can be established. This is optional. This URL can be found in the AWS API Gateway UI. It will be displayed in the terminal after deployment.
Now, integration is ready. Messages can already be loaded into the stream. The transport and processing still need to be implemented. Since there is no receiver for this data, the StepFunction will be the EventBridge pipe’s target instead of a transformer, for the sake of simplicity. It makes sense to start with its definition.
const sfnPassState = new Pass(this, 'Pass',{ outputPath: '$.[0]' });
In the first step, the first element of the message stack is forwarded. For the demonstration, the pipe bandwidth is set to 1. If it were larger, the map element would have to be used for processing.
const sfnWaitState = new Wait(this, 'Wait',{ time: WaitTime.duration(Duration.seconds(5)) });
Then a long process is simulated. Here, it is 5 seconds.
The next step is sending a response. However, due to an unsolved bug in the framework [5], a class must be created as a workaround. The problem is that it isn’t possible to pass a value from the input to the Path parameter because the dollar sign is missing in the default implementation (Path instead of Path.$).
class CallApiGateway extends CallApiGatewayHttpApiEndpoint { constructor(scope: Construct, id: string, props: CallApiGatewayHttpApiEndpointProps) { super(scope, id, props); } protected _renderTask(): any { const orig = super._renderTask() const ret = {}; Object.assign(ret, orig, { Parameters: {"Path.$": "States.Format('@connections/{}', $.body.connectionId)", ...orig.Parameters} }); return ret; } }
Now it will be used for creating the next step.
const response = { 'connectionId.$': '$.body.connectionId', 'longRunningRequest.$': '$.body.payload.Message', 'status': 'processed' } const sfnInvokeApiGatewayState = new CallApiGateway (this, 'InvokeApiGateway', { apiId: apiGateway.attrApiId, method: HttpMethod.POST, apiStack: Stack.of(apiGateway), requestBody: TaskInput.fromObject(response), stageName: apiStage.stageName, authType: AuthType.IAM_ROLE });
The response is the form of the response object with the attributes set accordingly. The reason why body occurs in the JSONPath becomes clear when the pipe is created. The connectionId and the payload are automatically added by VTL. The caller must specify the message.
The now-defined necessary steps have to be implemented into a state machine.
const stateMachine = new StateMachine(this, 'StateMachine', { definitionBody: DefinitionBody.fromChainable(sfnPassState.next(sfnWaitState).next(sfnInvokeApiGatewayState)), stateMachineName: 'new-serverless-sm', stateMachineType: StateMachineType.EXPRESS, // logs optional logs: { destination: new LogGroup(this, 'LogGroup', { logGroupName: '/aws/vendedlogs/states/new-serverless-sm-log-group', removalPolicy: RemovalPolicy.DESTROY } ), level: LogLevel.ALL, includeExecutionData: true } }); stateMachine.addToRolePolicy(new PolicyStatement({ actions:['execute-api:ManageConnections','execute-api:Invoke'], effect: Effect.ALLOW, resources: [`arn:aws:execute-api:${this.region}:${this.account}:${apiGateway.attrApiId}/*`] }));
Workflow type EXPRESS and optional logs for visual inspection. It is also important to assign write permissions to the API gateway, since these are not generated correctly because of the class extension. To illustrate the principle of operation, this is a very simple state machine.
The last step is the defining the EventBridge Pipe as transport medium between the Kinesis Stream and the StepFunction.
const pipeSourcePolicy=new Policy(this, 'PipeSourcePolicy', { statements: [new PolicyStatement({ actions: [ 'kinesis:DescribeStream', 'kinesis:DescribeStreamSummary', 'kinesis:GetRecords', 'kinesis:GetShardIterator', 'kinesis:ListStreams', 'kinesis:ListShards' ], resources: [kinesisStream.streamArn], })], }); const pipeTargetPolicy=new Policy(this, 'PipeTargetPolicy', { statements: [new PolicyStatement({ actions: ['states:StartExecution'], resources: [stateMachine.stateMachineArn], })], }); pipeRole.attachInlinePolicy(pipeSourcePolicy); pipeRole.attachInlinePolicy(pipeTargetPolicy); const pipe = new CfnPipe(this, 'Pipe',{ source: kinesisStream.streamArn, target: stateMachine.stateMachineArn, roleArn: pipeRole.roleArn, sourceParameters: { kinesisStreamParameters:{ startingPosition: 'LATEST', batchSize: 1 } }, targetParameters: { stepFunctionStateMachineParameters: { invocationType: 'FIRE_AND_FORGET' }, inputTemplate: '{ \"body\": <$.data> }' } });
First the role with permission to receive records from Kinesis and start the statemachine. For the source parameters, the read start position is set to LATEST to start receiving data with the latest entries. As previously explained, the batch size is 1. For the destination parameters, the situation is a little more interesting. The call type can be set to wait for the end of the StepFunction, blocking the pipe, or, as it is here, asynchronous. The input template packs base64-decoded data from the stream under the body key. This is also expected by the StepFunction.
Done. Now all that’s left is providing the infrastructure: cdk deploy
Output: NewServerlessStack.WebSocketURL=wss://ygfumhmnv7.execute-api.eu-west-1.amazonaws.com/dev
The tests can be performed with wscat or an online tester. Here, we have used wscat.
wscat -c “wss://ygfumhmnv7.execute-api.eu-west-1.amazonaws.com/dev”
Connected (press CTRL+C to quit)
> {"action":"notExisting", "Message":"test"} <{"message": "Forbidden", "connectionId":"J0GNIevmjoECEGQ=", "requestId":"J0GVgFH6joEFxCw="} > {"action":"longRunningRequest", "Message":"test"} <{"status":"processed","connectionId":"J0GNIevmjoECEGQ=","longRunningRequest":"test"}
If the action is specified incorrectly, an error is displayed. Otherwise, the response comes back as expected after approximately 5 seconds. The requests can be sent directly one after the other.
> {"action":"longRunningRequest", "Message":"test1"} > {"action":"longRunningRequest", "Message":"test2"} < {"status":"processed","connectionId":"J0GNIevmjoECEGQ=","longRunningRequest":"test1"} < {"status":"processed","connectionId":"J0GNIevmjoECEGQ=","longRunningRequest":"test2"}
The responses also come one after another.
It is recommended that you add more API routes and EventBridge pipes, especially with action filtering. This is part of further evaluation to realizing the full potential of an event-driven architecture on AWS. Extending the pipe for pre-filtering requires specifying filterCriteria in sourceParameters.
sourceParameters: { filterCriteria: { filters: [ { pattern: JSON.stringify({ 'data': { 'payload.action': ['longRunningRequest'], }, }), }, ], },
In diesem Beispiel werden nur Nachrichten mit action longRunningRequest weitergeleitet. Weitere Patterns sind in der Dokumentation zu finden [7].
A critical look
From today’s perspective, the answer to if Lambda functions are a thing of the past in the AWS ecosystem is a “no”. However, it’s clear that they should mainly be used for computing domain logic instead of acting as glue for services. The moment an attempt is made to move the presented solution into production, developers encounter a number of problems. It turns out that when there are errors in the EventBridge pipes, the logs aren’t much help and the fix must be sought out on its own. In many cases, documentation is insufficient and you need to contact support directly for assistance. Regarding StepFunctions, a lot of development work still needs to be done to make this service perfect. The sample implementation presented makes it clear that the API still has potential for better automation. Keep in mind that developers are used to writing code, and there will often be voices on your team that go against this kind of workflow orchestrator. However, the reality is that AWS is focused on developing configuration-over-code solutions, so jumping on this bandwagon quickly may make it easier to work on current and future projects.
References
[1] https://youtu.be/RfvL_423a-I
[2] https://docs.aws.amazon.com/step-functions/latest/dg/amazon-states-language-intrinsic-functions.html
[3] https://docs.aws.amazon.com/cdk/v2/guide/home.html
[4] https://velocity.apache.org/engine/devel/vtl-reference.html
[5] https://github.com/aws/aws-cdk/issues/14243





